Last month I presented this talk at MeasureCamp Melbourne. BUT that wasn’t enough. Today I’m sharing here as this information is important for everyone in marketing to understand. This is how you should be optimising for crawlers and agents (and no, they’re not the same thing).

Optimising for crawlers and agents: Two faces, one formula.
For nearly three decades, we optimised for one gatekeeper: Google.
All that time, we’ve been trying to reverse-engineer the algorithm. And to be fair, we got pretty good at it. But so did everyone else. That’s where the problem starts.
I call it the apple pie effect.
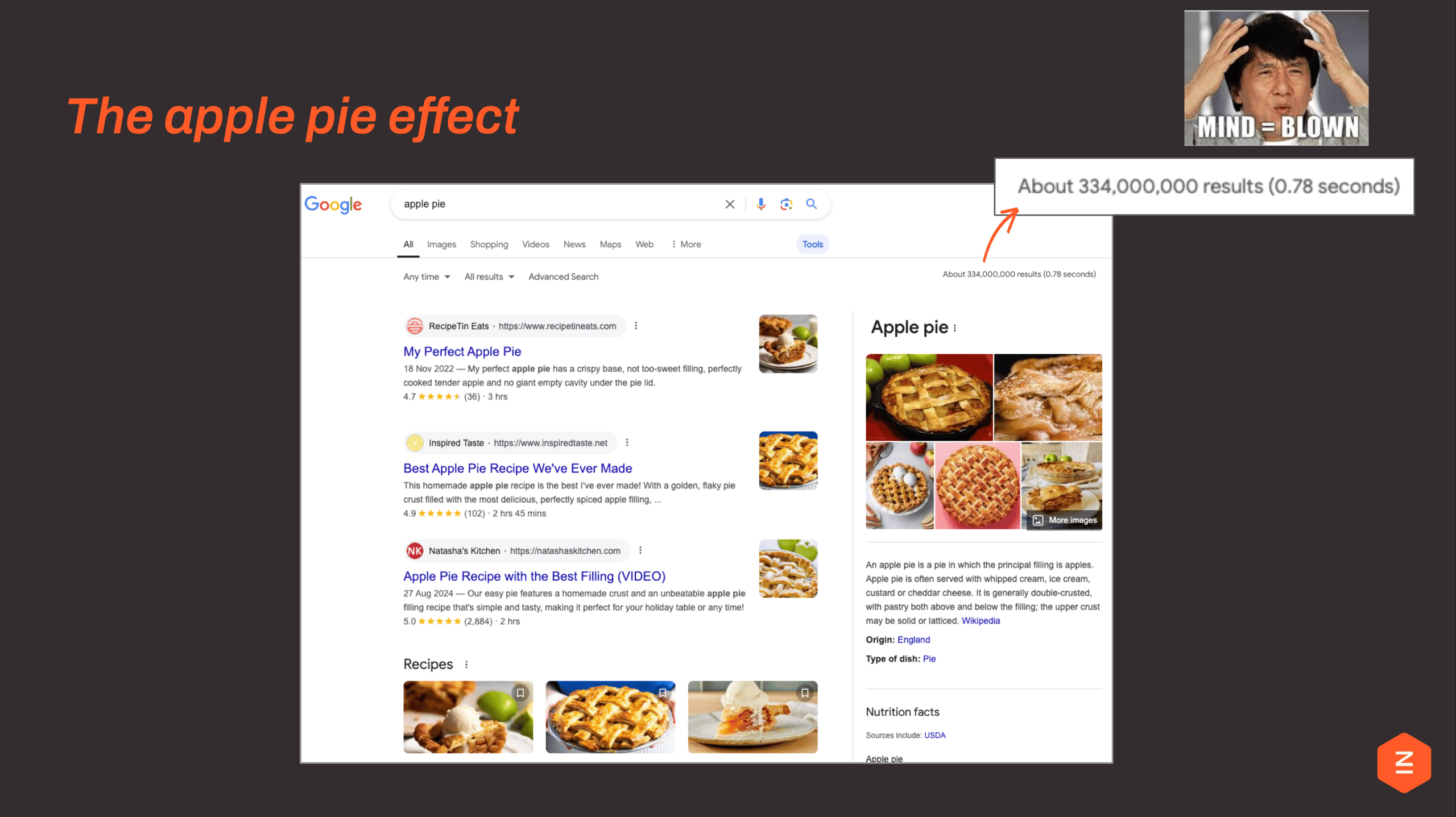
Search for something as simple as “apple pie” and you’ll find over 300 million results. But we don’t need 300 million apple pie recipes. What’s happened is we’ve optimised for ranking, not for differentiation. The result? Content that is increasingly interchangeable, and far too much of it.
Now fast forward to today.
- Those 300 million results still exist. But users aren’t really seeing them anymore. Instead, they’re presented with a single answer, curated, summarised, and decided for them.
- AI isn’t ranking content. It’s selecting what it trusts.
- And suddenly, the question isn’t “how do I rank?”
It’s:
- Why would I be chosen?
Because when we move from 300 million results to one answer… something fundamental changes.
We stop clicking.
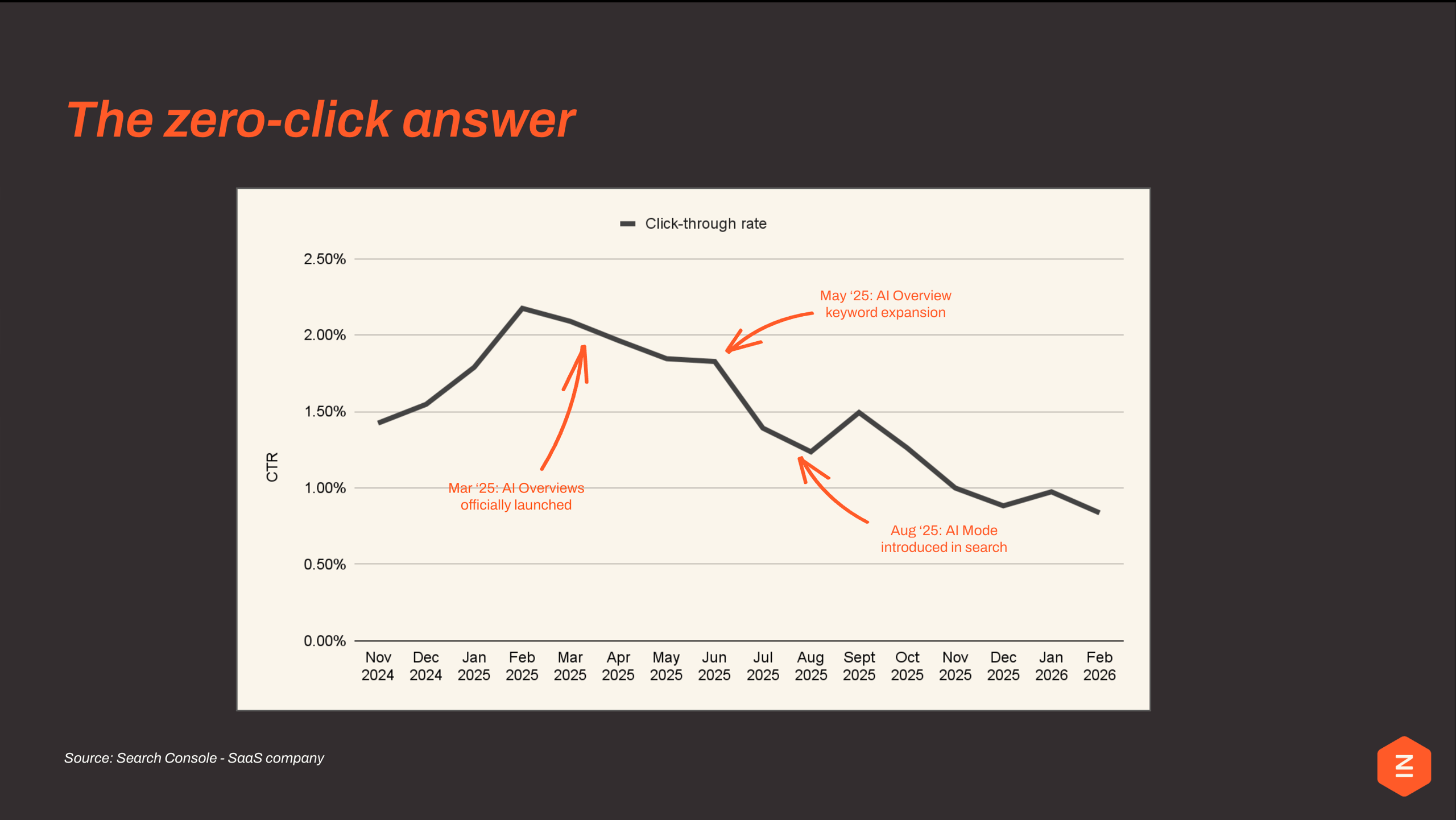
The data is already showing it. As AI Overviews rolled out, click-through rates didn’t just fluctuate — they declined. March: launch. A peak, then a drop. May: expansion, further decline. August: full AI mode, another step change down.
This isn’t a temporary dip.
It’s a behavioural shift.
The numbers don’t lie. And they’re uncomfortable.
Zero-click search is real and accelerating
Search Console data from a SaaS client shows CTR peaked at around 2.25%, then fell off a cliff. Three things caused it, each one compounding the last:
A crawler and an AI agent are not the same thing at all
This is where a lot of people get confused. They assume AI search works like Google search, just a smarter version. It doesn’t. The underlying mechanism is completely different, and that changes everything about how you prepare for it.
A traditional crawler is basically a filing system. It scans your page, matches it to keywords, and counts who links to you. It doesn’t understand anything. An AI agent genuinely reads your page, judges whether your content is accurate, credible, and worth quoting, then writes a direct answer and cites whoever it trusts most.
Search Crawler (the old way)
→Matches your keywords to a query
→Counts links pointing to your page
→Returns 10 blue links to humans
→It indexes: it does not understand
→Users evaluate results themselves
LLM / AI Agent (the new way)
→Reads and comprehends your content
→Evaluates credibility and accuracy
→Synthesises a direct, cited answer
→It understands: it does not just index
→Users get the answer. No click needed.
One files. One reads. You can’t game a system that genuinely reads.
There are three ways an AI can find your content. Only one is really in your hands.
Not everything is within reach, so it’s worth knowing exactly where to focus your energy.
Training Data
Largely uncontrollable
→Pre-baked knowledge
→Potentially outdated
→No attribution
→Lack of control
RAG / Retrieval
Primary lever for AI Visibility
→Pulls live web content
→Surfaces and cites trusted sources
→Influenced by technical SEO + content quality
Agent Browsing
The future?
→AI navigates your website
→Interprets content, UX and performance
→Influenced by structure and accessibility
RAG (Retrieval-Augmented Generation) is the one to prioritise. It means the AI fetches live pages from the web at the moment a question is asked, then uses those pages to build its answer. This is where good SEO and AI visibility directly overlap.
Two faces. Three pathways. One formula.
It always comes back to the same three things. Whether you’re trying to rank on Google or get cited by an AI, you need all three of these to work together:
AI systems can reach your content
Content structured for machines
Authority earns citations
Miss any one of them and the other two don’t matter. Let me walk through each.
First things first: can AI bots actually get to your site?
Crawlability
A surprising number of teams have blocked AI crawlers in their robots.txt, sometimes intentionally, often by accident. They were trying to manage server load or protect content, and didn’t realise what they were opting out of.
Googlebot is no longer the only bot that matters. Look at the crawl data below. Meta, OpenAI, Anthropic, Amazon: they all send their own crawlers now, and the volumes are significant. Blocking them means choosing invisibility in AI answers and training data.
Share of AI Crawl Activity (No. of Crawls, Logs)
Meta-ExternalAgent
ChatGPT-User
GPTBot
ClaudeBot
AmazonBot
OAI-SearchBot
PerplexityBot
Beyond the bots themselves: clean internal linking, fast loading speeds, and lean HTML all matter more than ever. AI crawlers have limited budgets and no patience for bloated pages.
If it needs JavaScript to appear, it doesn’t exist for most AI
Performance and Renderability
This one catches people off guard. A page that looks great in Chrome can be completely empty to an AI crawler. If your content is loaded by JavaScript, filtered behind a widget, rendered dynamically, many AI agents simply can’t see it.
We actually captured a live example of this. ChatGPT’s Agent mode browsed a page and saw nothing because the articles were hidden behind a JS filter. The content existed. The AI just couldn’t access it.
- Bloated DOM = more tokens to parse. Keep your HTML lean
- Use semantic HTML5:
<header><main><footer>. These give structure agents can follow. - Async/defer scripts to prevent render-blocking that hides content from agents
- Images without dimensions cause layout shifts that confuse agent screenshots
Accessibility works for machines too
Accessibility
Accessibility and SEO have always been the same investment. The AI era just proves it. The same signals that help screen readers navigate your site are the ones AI agents rely on to understand it.
- Alt text is how AI reads your visuals. No alt text = invisible content. Simple as that.
- ARIA landmarks (
role="navigation",role="form") and lang attributes give AI structural understanding of your page - “Click here” tells agents nothing. “Download our Apple Pie Recipe” tells them exactly what to expect on the other side
AI reads your page the way a skimmer does: headings first, details second
Content Architecture
Imagine handing your page to someone who will skim it in five seconds and then answer a question about it. If they can’t tell what the page is about from the headings alone, they’ll get it wrong, or skip it entirely. That’s exactly how an AI agent works.
- Use a clear heading hierarchy. One H1, logical H2s, structured H3s underneath.
- Write descriptive, literal headings. Not clever ones. “How Campaign Attribution Works” beats “Making Magic Happen” every time.
- Start with the answer. Don’t make an AI wade through three paragraphs of context to find the point.
- Build topic clusters, not isolated pages. Depth of coverage signals genuine expertise.
Lump of Text ✗
→AI: What exactly does this tool do?
→AI: No clear use case or audience
→AI: Too vague to extract meaning. Skipping.
Structured Content ✓
→AI: Clear purpose (marketing analytics)
→AI: Structured and scannable sections
→AI: Easy to understand and cite
Schema markup: the invisible layer AI actually reads
Structured Data
Schema markup is code you add to your pages that labels what things are: “this is the author”, “this is the price”, “this is a FAQ answer”. Users never see it. AI systems absolutely do. And Fabrice Canel from Bing said it directly:
“Schema markup helps Microsoft’s LLMs understand your content”
Fabrice Canel, Bing
The three schema types to prioritise first:
Organisation
→Connects your brand name, logo, founding date, social profiles and key people to the knowledge graph
Article /
BlogPosting
→Attaches a named author, publish date and modification date. The signals AI trusts most.
Product / FAQPage
→Gives AI parseable pricing, availability and Q&A data: the exact facts that get pulled into AI answers
Source: searchengineland.com
The simplest advice: just write well
Content Clarity
The single biggest content mistake out there is pages written for algorithms: packed with keywords, watered down, generic. AI is going to sort through the noise faster than any human ever could. What survives is the stuff that’s genuinely useful.
- Write for humans, not algorithms. Natural, clear language beats keyword-stuffed copy.
- Add unique, specific insights. Data, facts and concrete examples outperform generic statements.
- Keep content fresh. Recency signals matter: updated content is more likely to surface in AI results.
Machines don’t trust content. They verify entities.
Authority & Trust Signals
This is what changes everything about how we think about SEO. It’s not about your page anymore. It’s about your brand, your authors, your presence across the web.
An entity is a clearly identifiable thing: a named person, a recognised brand, that exists consistently across multiple credible sources. AI systems are far more likely to cite entities they can verify than anonymous pages they can’t.
- To build that kind of trust signal:Named expert with verifiable credentials: author bios, LinkedIn, publications
- Consistent entity presence across the web: the same brand and people appearing on reputable third-party sites
- Citations and references to primary sources within your content
- Clear freshness and update signals: explicit publish and modification dates
The good news: you don’t need a completely new strategy
Google or AI? The same investment serves both.
People often assume AI visibility is a separate workstream, a new thing to do on top of everything else. It mostly isn’t. Look at what sits in the middle column below. That’s where almost all of your budget should go, and it’s the same work that’s always driven SEO results
Google Only
→PageRank & Backlinks
→Core Web Vitals as ranking factor
→SERP feature targeting
→Local pack optimisation
→User clicks, reads, decides
Shared Ground
→Quality, expert-led content
→Structured data
→Site architecture & internal links
→Entity clarity & E-E-A-T
→Brand visibility
AI Only
→Machine readability of HTML
→AI Crawler Access
→Data specificity
→JS-free content delivery
The shared ground is where every pound you spend compounds. Start there.
Agents won’t just answer questions. They’ll complete the whole transaction.
Think further ahead than AI summaries. The next step is AI agents completing tasks on a user’s behalf: browsing, comparing, booking, buying. Without the user ever choosing manually.
In that world, technical accessibility stops being a nice-to-have. It becomes the difference between existing as an option or being skipped entirely.
User: “Order a pre-baked apple pie for under $25 because I don’t like baking”
Agent:
Step 1: Browse shop-a.com ………… $19 found
Step 2: Browse shop-b.com ………… ERROR: JS widget
Step 3: Browse shop-c.com ………… $29 found
Step 4: Compare and recommend …….. shop-a wins
Step 5: Complete bookings
Result: Shop B lost the sale. Not because of price. Because of accessibility.
Shop B wasn’t more expensive. Shop B wasn’t worse. Shop B just couldn’t be read.
Conclusion
It isn’t a technical problem.
It is a brand problem opportunity.