LLMs are powerful tools for content generation, but understanding their limitations and avoiding misleading analogies to human intelligence is crucial for their effective use. Here, I’ll present you with an argument of sorts, as to why the language that we use to describe LLMs is misleading people, including LLM hallucination and other AI misnomers.
I’ll start with how we use LLMs at In Marketing We Trust, then how the term hallucination is being used for LLMs. This will be followed by a high-level overview of what happens when an LLM generates content, we’ll go into the “strawberry problem”, and we’ll also look at the terms “thinking” and “reasoning” and how they are applied to LLMs. Then we’ll dive into why this matters
How We Use LLMs at In Marketing We Trust
Over the past 1.5 years, our team has generated over 100,000 pieces of content for the web across 13 markets and 9 languages. The process involves data gathering and validation (human-driven with AI assistance), AI-driven content generation, and human-driven content review.
Read one of our case studies on LLMs here.
Challenges
Over this time we have faced, and continue to face many challenges, which is why we have a high degree of human involvement. A couple of quick examples that you can replicate at home if you wish are:
- Every city is vibrant – ask an LLM to generate content about a city, it will be vibrant in some way, regardless if it’s Paris, or a small city in the middle of Burkina Faso, Africa
- Another is to try to get an LLM to consistently output in either British English or American English spelling, or worse, Canadian English (a mix of both)

LLM Hallucination
Let’s take a look at what hallucinations are in people and compare that to what is being referred to when we talk about LLM hallucination.
What is hallucination in people?
“A hallucination is a false perception of objects or events involving your senses: sight, sound, smell, touch and taste. Hallucinations seem real, but they’re not. Chemical reactions and/or abnormalities in your brain cause hallucinations.” – Source: Cleveland Clinic
What is LLM hallucination?
“LLM hallucinations are the events in which ML models, particularly large language models (LLMs) like GPT-3 or GPT-4, produce outputs that are coherent and grammatically correct but factually incorrect or nonsensical. “Hallucinations” in this context means the generation of false or misleading information. These hallucinations can occur due to various factors, such as limitations in training data, biases in the model, or the inherent complexity of language.” – Source: Iguazio

This is Bob, an AI generated rainbow zebra, if you see him walking around you might want to seek medical attention.
What is LLM Hallucination?
In our brains, a hallucination is a malfunction of the internal operation. For LLMs it’s an incorrect output, nothing about the internal functioning.
Using “hallucination” for LLMs suggests an abnormal event occurred to produce the incorrect output, which implies a number of things:
-
- Occurrences are rare
- Not frequently repeatable
- Shifts accountability – we don’t blame people for their actions when they are hallucinating
Next time someone tells you something that you know is wrong, try telling them they are hallucinating – see how that goes down…
How LLMs Work
Before we go further into detail around how the terms we’re applying to LLMs affect how people are using them, I’m going to share a high-level overview of what LLMs are doing when generating output.
Please note that this is not a deep dive into the details of how LLMs work. This is just to provide a base level of context to help reason about the operations, and has been simplified for this purpose.
A massive data set is used to train a model, this process has multiple steps:
-
- A model is a system that learns from data
- A neural network is a type of model, a neural network is a way to fit data to an arbitrarily complex mathematical formula
- An LLM is a specific type of neural network, called a transformer, that is designed to process and generate text
- In an LLM words and characters get converted into tokens (identified by a number, a token ID), which can be whole words or parts of words
- Tokens are mapped to vectors, which are sets of numbers, that are calculated so that different dimensions represent the similarity of some word => This makes it so that “cat” will be close to “dog” because they are both pets, both animals, both furry, etc. This is learned by the computer from the context in which the words are used, the attribution of why two words are similar is done by humans and is not how a computer “thinks” about it
- The model is fed massive amounts of example text to set up the model
- The model also has “attention” – see Attention is All You Need – which allows the model to weigh some parts of text more heavily than others, this is also used in the generation (or inference) process
Once a model has been trained, it can be used to predict the most probable next token based on the input, and where it’s up to in the output.
There are some settings that you may have seen when working with LLMs, Temperature, Top K, and Top P. Top P and Top K are ways of adjusting the set of possible tokens to consider as candidates. Temperature is a way of adjusting the amount of randomness in token selection, as there are likely many good next-token options.
Attention is another part of an LLM, which again, is used to identify tokens of importance, this time in the context of the prompts and output. As the next token is selected, the entire context (prompt and generated content so far) is fed back in, to predict the next token.

Understanding that this is what the LLM is doing will be important for the next sections – the LLM is predicting the next tokens to add to the context, which becomes the output.
Examples of LLM Hallucination
For an example LLM hallucination let’s take a look at what has been a very famous “hallucination” in recent months: counting the number of Rs in strawberry.
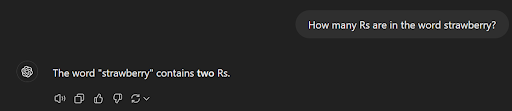
How many people have seen something similar to this in their social feeds? This seemingly simple question tripped up even the most up-to-date models, up until the launch of OpenAI’s o1 models.
When the LLM outputs the token for “two” instead of the token for “three”, internally it is just calculating what the most likely next token is. Nothing about this process is about the model malfunctioning in order to produce the incorrect number, like the term hallucination would imply, it just means that the data it was trained on resulted in the next token being more likely to be “two” instead of “three”.
It highlights the importance of understanding what an LLM can and can’t do, in this case counting.
LLM Hallucination: Thinking & Reasoning
In this section we’ll be looking at the terms “thinking” and “reasoning” and how they are used in the context of LLMs.
We will take a look at some findings from a recent paper about reasoning benchmarks for LLMs. And we consider the differences in performance with open benchmarks, where the prompts and answers are publicly available, and closed benchmarks where they are not.
How OpenAI Describes Its o1 Models
Here is how OpenAI describes its o1 models:
- “We’ve developed a new series of AI models designed to spend more time thinking before they respond.”
- “o1-preview has strong reasoning capabilities and broad world knowledge.”
- “These models can reason through complex tasks and solve harder problems than previous models in science, coding, and math.”
These descriptions are great from a marketing perspective. They do have additional capabilities that make them more powerful. But is it “reasoning”?
The Reasoning Misnomer

Here we have a section taken from the paper: GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models.
On the left, you have the prompt and expected answer for GSM8K, which is a reasoning benchmark for LLMs, where the prompts and answers are open.
In this example, there is a person, Sophie, her nephew, and a bunch of different toys. The goal is to determine how many of the toys were bouncy balls when provided with the numbers of other types of toys, and the total number of toys.
On the right, you have the modifications by the paper’s authors, where instead of providing a static prompt where the name, family member, and values are known, they are replaced dynamically before being sent to the LLM. So instead of Sophie and her nephew, it might be Bob and his brother.
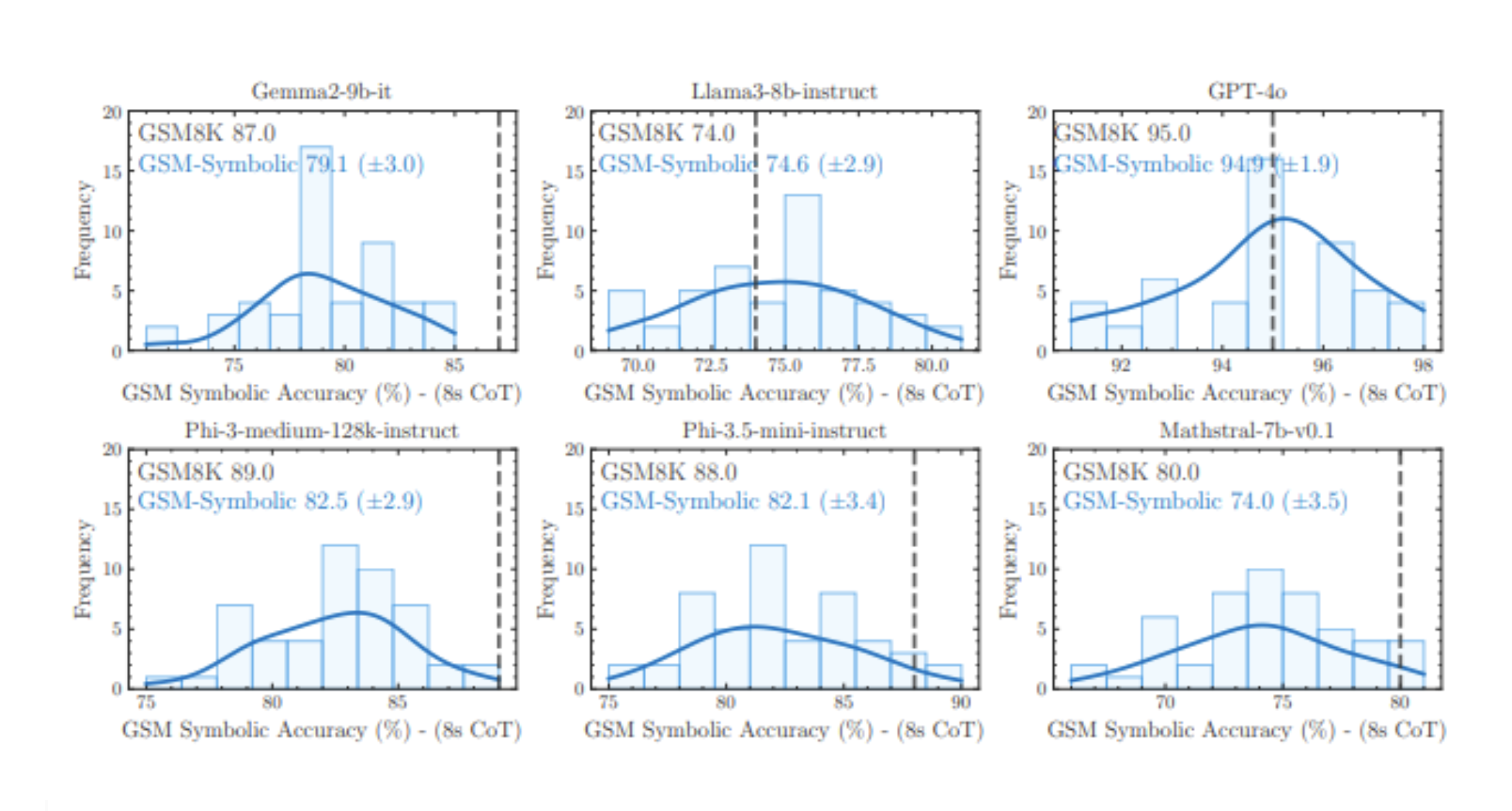
This generally results in a decline in performance, despite the fact that the “reasoning” required to solve the problem hasn’t changed.
This image, also taken from the paper, shows a general decline in performance in these benchmarks across multiple models, when given 8 attempts at reasoning through the problem – referred to as 8 shot Chain of Thought.
It is important to note that we’re looking at accuracy levels in the 70, 80 and 90 percent ranges for open benchmarks. The paper goes on to modify the GSM8K prompts further in different ways, resulting in further reductions in LLM performance.
What about reasoning in closed datasets?
When we look at a closed benchmark, the numbers look quite different.
While humans average 92% on this dataset, the best LLM that has been tested, Claude 3.5 Sonnet, averages 27%. When comparing that to the scores in the 70, 80 and 90 ranges on open benchmarks, it suggests that LLMs are being trained on the open benchmarks prompts and answers.
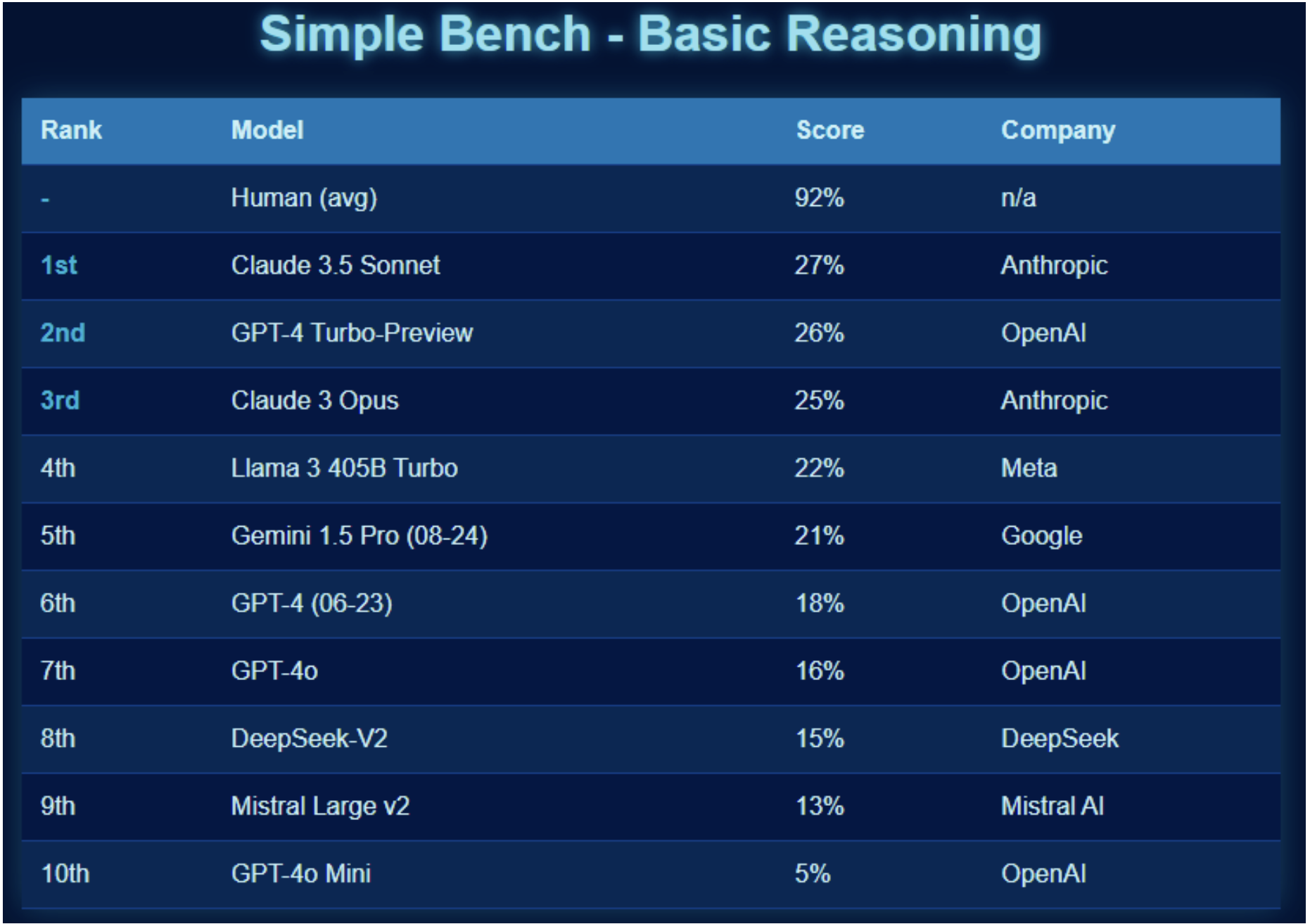
Source: Simple-bench.com (October 2024)
Should we call this reasoning?
Now for the big question: Should we call this reasoning?
We have seen that small changes to the input results in declining performance in the output. The additional reading shows the further you get from the original text from the benchmark, the more the performance degrades. There seems to be a huge gap between the performance of LLMs on open benchmarks compared to closed ones.
If I hand you an exam, and the answer sheet, would you have reasoned about any of your answers?
In models like OpenAI’s o1, it’s the LLM’s ability to reproduce the reasoning of others, not its ability to reason that is being tested. The evidence suggests that it is not capable of taking concepts and applying them to solve a new problem.
LLM Hallucination: Why it Matters
We’re going to take a look at some social media posts now. The intention is not to point and laugh at people who are getting things wrong, it’s to take a look at the part that the language and analogies play in people arriving at these conclusions.
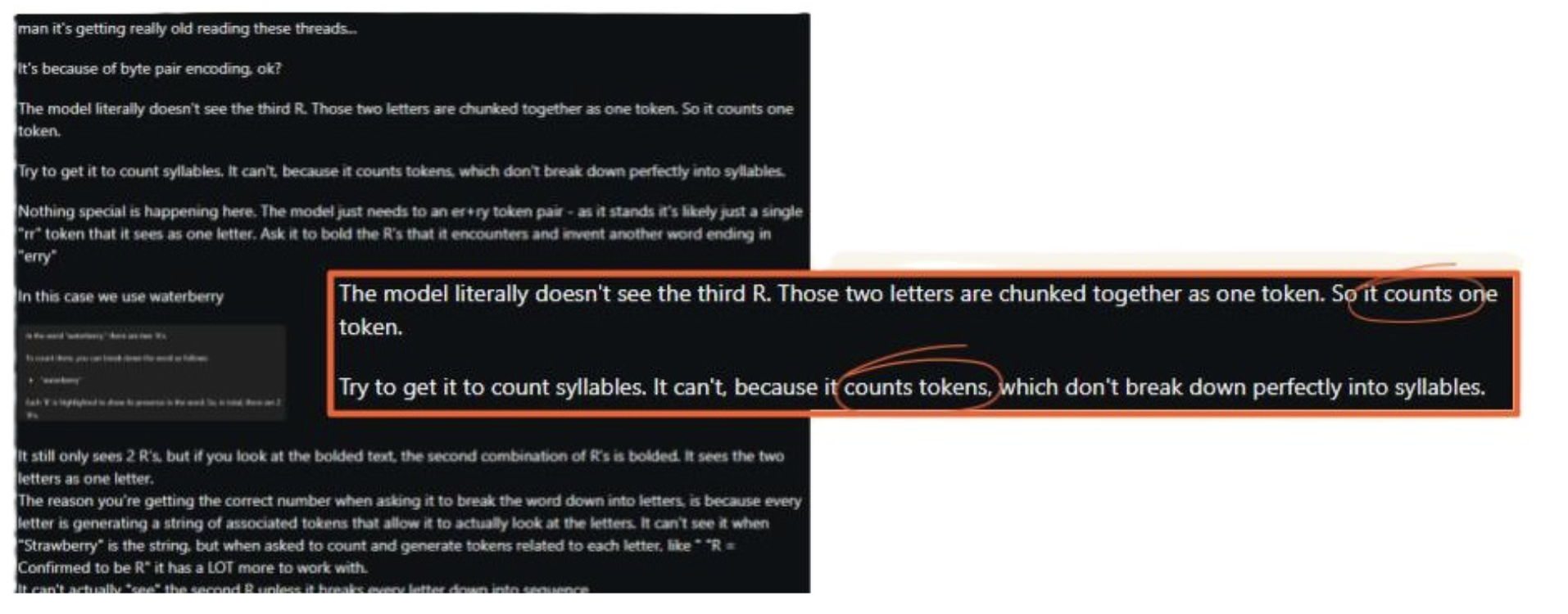
So there are a couple of problems with this post, but it stems from the misguided idea that LLMs can count anything. As explained, LLMs are predicting what the next token is most likely to be, based on the data it has been trained on, and the context that it currently has.
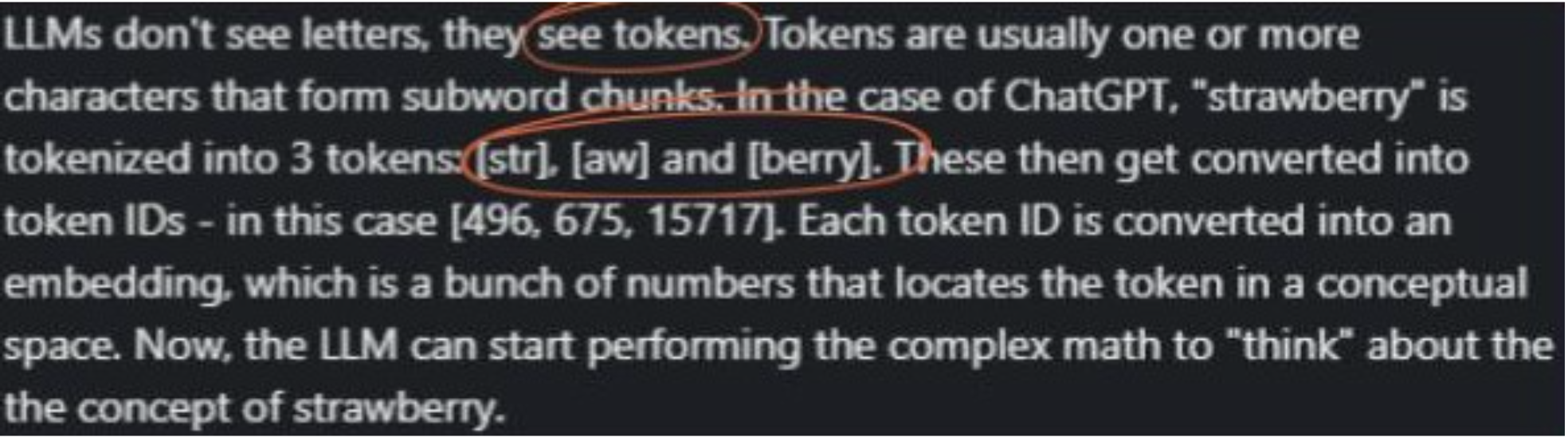
So here we have the concept of seeing tokens. And also an assertion that “strawberry” gets broken into three tokens. Let’s look closer at that.
Note that this is from a VP of AI, at a company that has been researching natural language AI for over a decade.
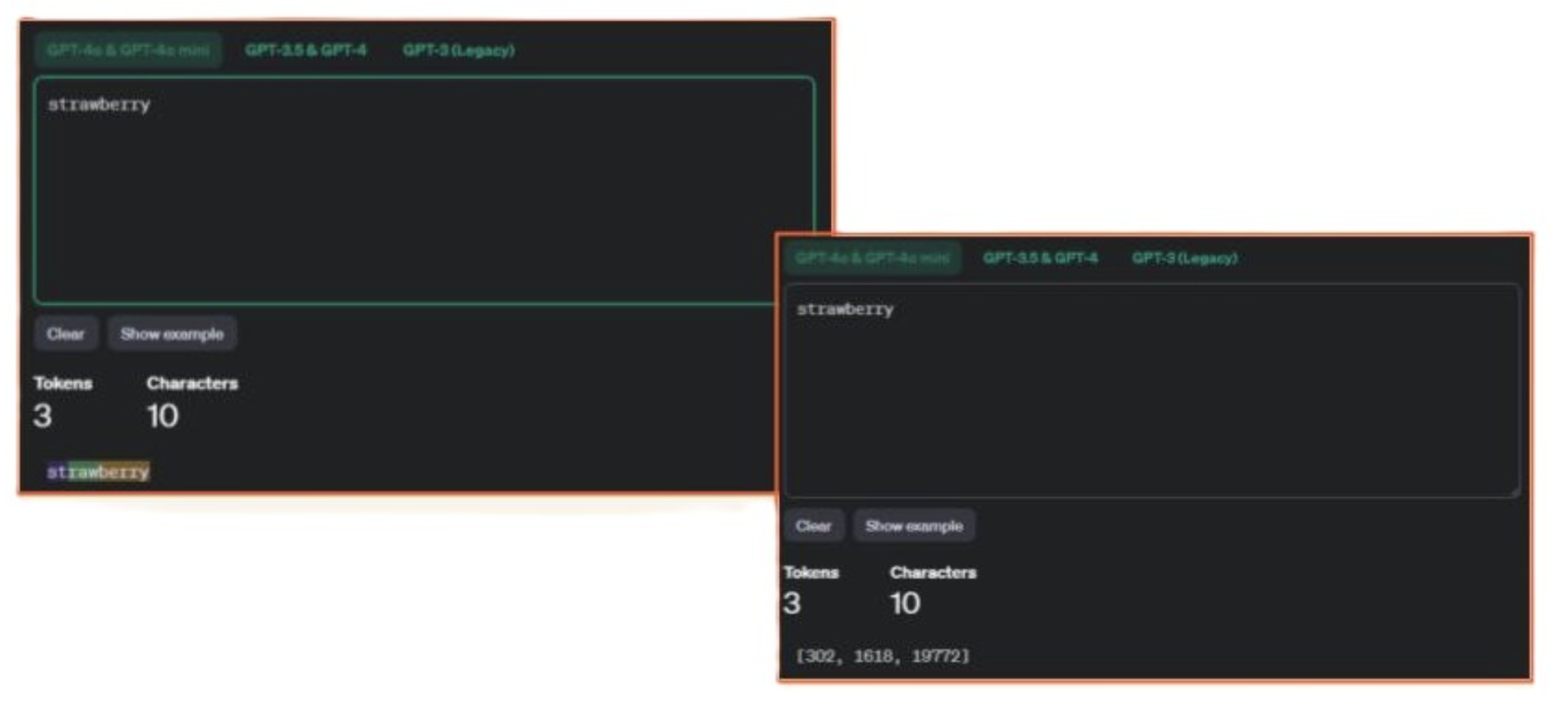
If you enter strawberry on its own into the OpenAI Tokenizer, it will show you 3 tokens – the IDs will be different depending on which model you choose, but it looks right, right?
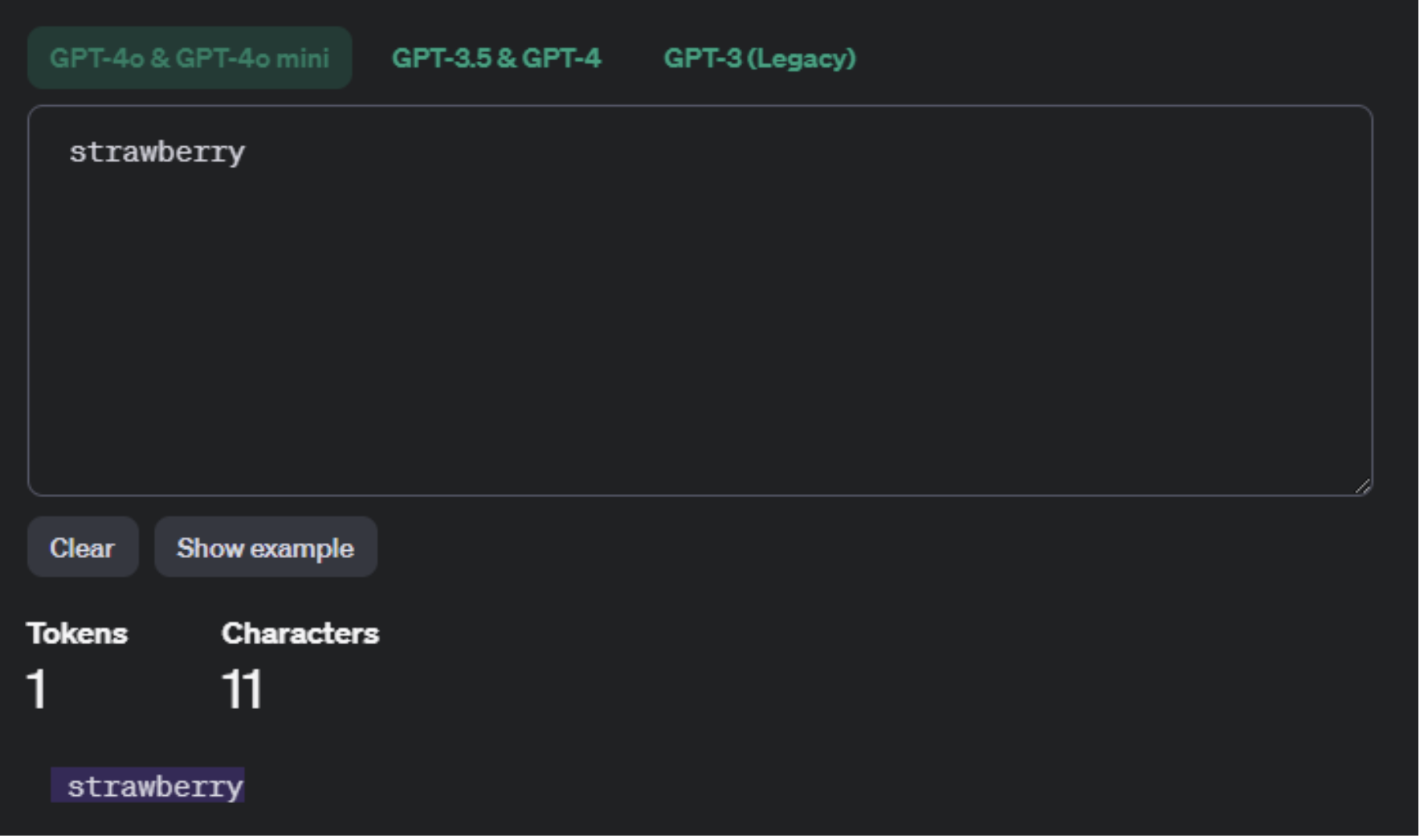
However, if you add a space before the word, like it would have in a sentence, it becomes one token.
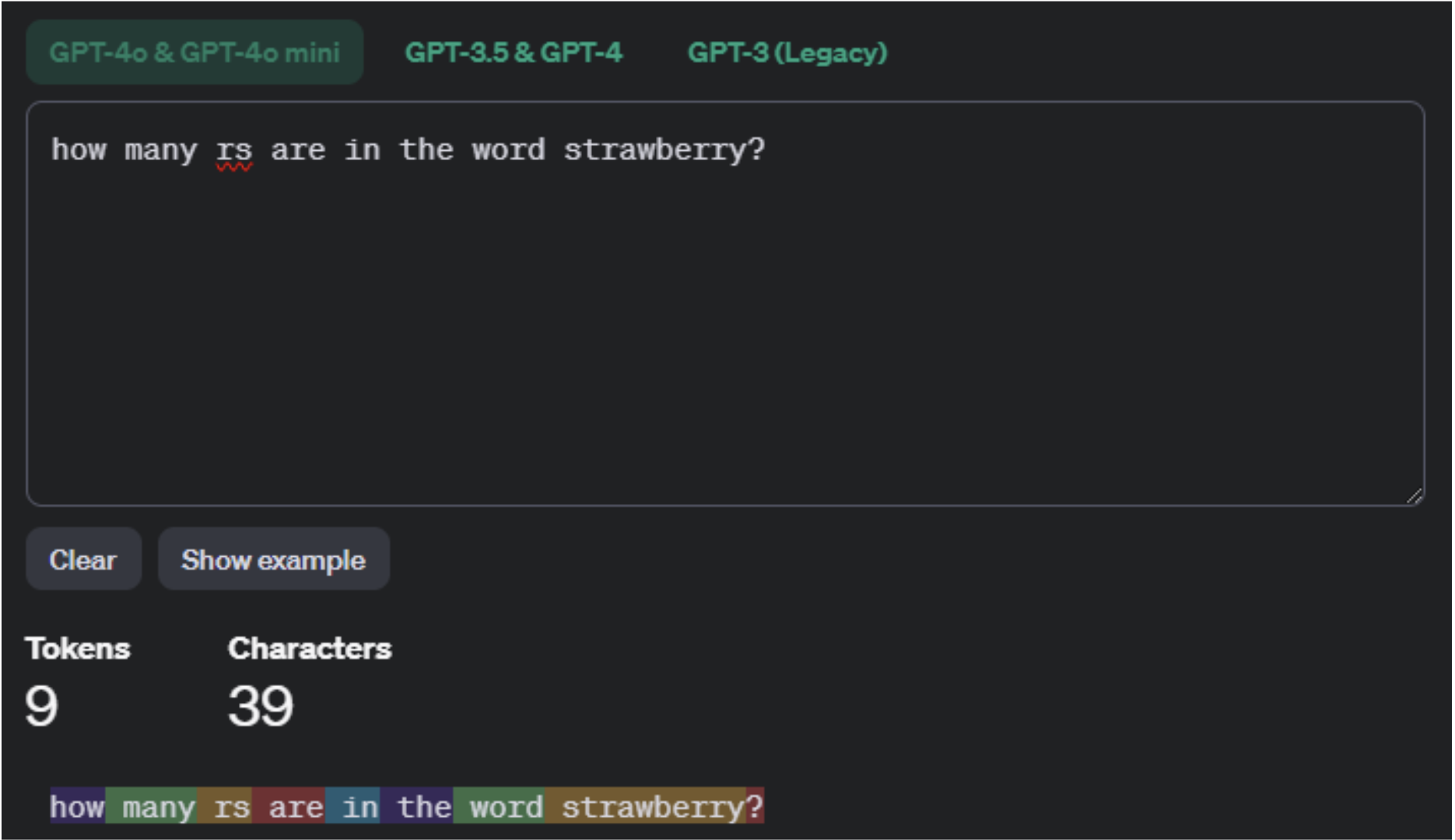
Here you can see it in a sentence, and strawberry remains as one token.
The assertion that many people make is based on the human reasoning that if “strawberry” is split into three tokens, and two of those tokens contain Rs, that that is the reason LLMs output 2 instead of 3, which seems logical.
The fact that it’s actually 1 token – wouldn’t that mean that it would be outputting 1 and not 2? The logic of these claims breaks down here.
There are many more posts like this.
A lot of people, including Senior AI Researchers, LLM Researchers, AI Engineers, are all citing the tokenization as the cause of LLMs not being able to count the number of Rs in strawberry.
It’s an easy mistake to make when so many discussions about AI are using analogies from human intelligence to describe its behaviour.
Conclusion
Many misconceptions about LLMs, including from senior AI researchers, stem from using human intelligence analogies to describe LLM behaviour. It’s important to be cautious when discussing LLMs, explain analogies, and understand that while progress is rapid, true AI thinking and reasoning are not yet achieved. LLMs are useful tools, but understanding their limitations is crucial for effective use.
- Take care when talking about LLMs, if you’re not sure someone understands LLM hallucination an analogy, explain it to them.
- At some point in the future, AIs will be able to think and reason in the way that we understand humans to, but we’re not there yet.
- Technical and non-technical people alike can be misled by attributing the human versions of the word to LLMs.
- LLMs are a really useful tool, but gaining some deeper understanding of how they work will help you determine what tasks they can help you with, and those that it can’t.
- Beware of benchmarks, consider what they are really testing.
And remember, LLMs don’t hallucinate.
This article was created based on a presentation given in October 2024. While the basis of the information remains relevant, there have been new models released since that are absent due to this.