Mo’ Pages, Mo’ Problems or: Why We Chose to Build a Web Crawler
Suffering from too many pages? This is the story of why we chose to build a web crawler ourselves, instead of using an existing tool. Why is our web crawler special?
- Its speed and capacity to handle huge amounts of data.
- The kinds of data it can capture.
History
In late 2016 we faced a dilemma: we needed to capture a snapshot of all the internal links on a site with around 12 million pages so that we could do a large scale analysis to show which links in which modules linked to which kinds of pages and recommend changes in link generation logic.
The obvious way to get this link data was through crawling the site. So we set to work evaluating web crawlers in order to pick the one most fit for purpose.
Loosely there are two types of crawlers:
- Programs such as Screaming Frog where you download the software and it runs the crawl on your local computer and writes data to a local file.
- Hosted solutions such as Botify where you configure a crawl through a web interface, the crawl runs on their servers and writes data to their database, and they provide an interface to view reports on the results of the crawl and export data.
There are a lot of great tools that fall into either category, but after an exhaustive search we found none of them quite fit our use case.
The problem we had with local crawlers was that they’d quickly suffer while crawling huge sites. Often we’d begin having issues with memory use at around 200,000 pages, let alone 12 million.
The issue with hosted crawlers was that there was a significant expense associated with crawling as many pages as we required and we only required a fraction of their functionality – i.e. we needed the actual crawl functionality, but our reporting needs were on a level beyond what they supported. There were also issues with accessing data hosted remotely on a database we didn’t have access to.
So after considering all our options – and doing a lot of soul searching to ensure we weren’t unnecessarily reinventing the wheel – we did what any good collective of nerds would do and chose to build a web crawler to cater to our own unique needs.
Crawling 101
At their heart crawlers are super simple software. You give them a starting URL and they download its HTML and extract the links. More advanced crawlers may also implement JavaScript engines which will run any onload JavaScript and scan for elements which act as links.
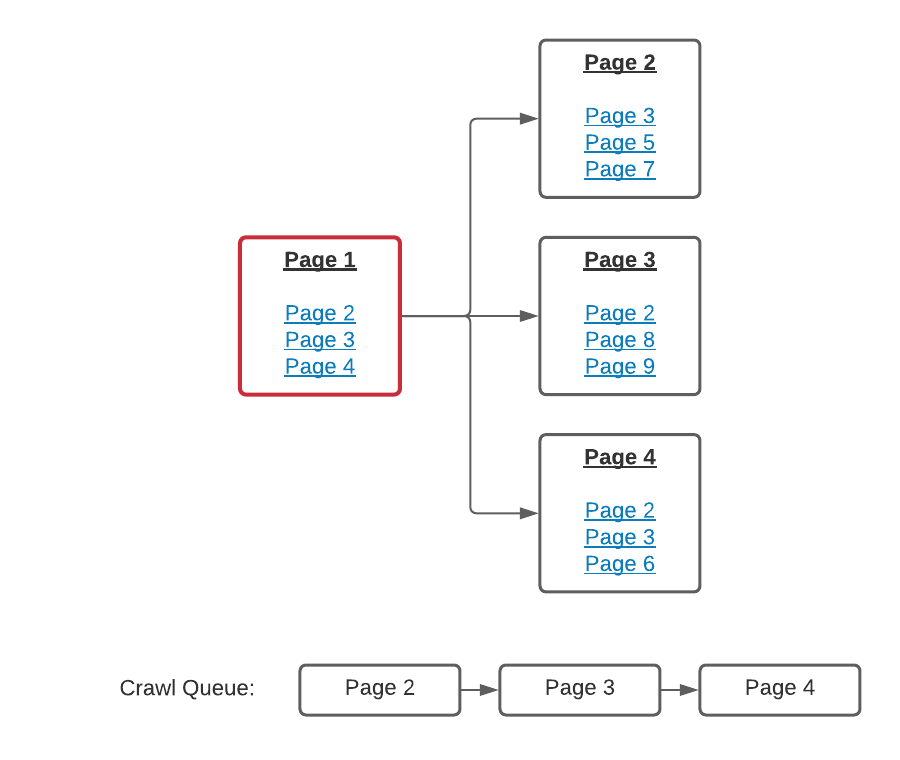 After all the links on a page have been collected they’re added to a queue of pages to be crawled. Then the next page waiting on the queue is crawled, the HTML is downloaded for it and those links are added to the queue.
After all the links on a page have been collected they’re added to a queue of pages to be crawled. Then the next page waiting on the queue is crawled, the HTML is downloaded for it and those links are added to the queue.
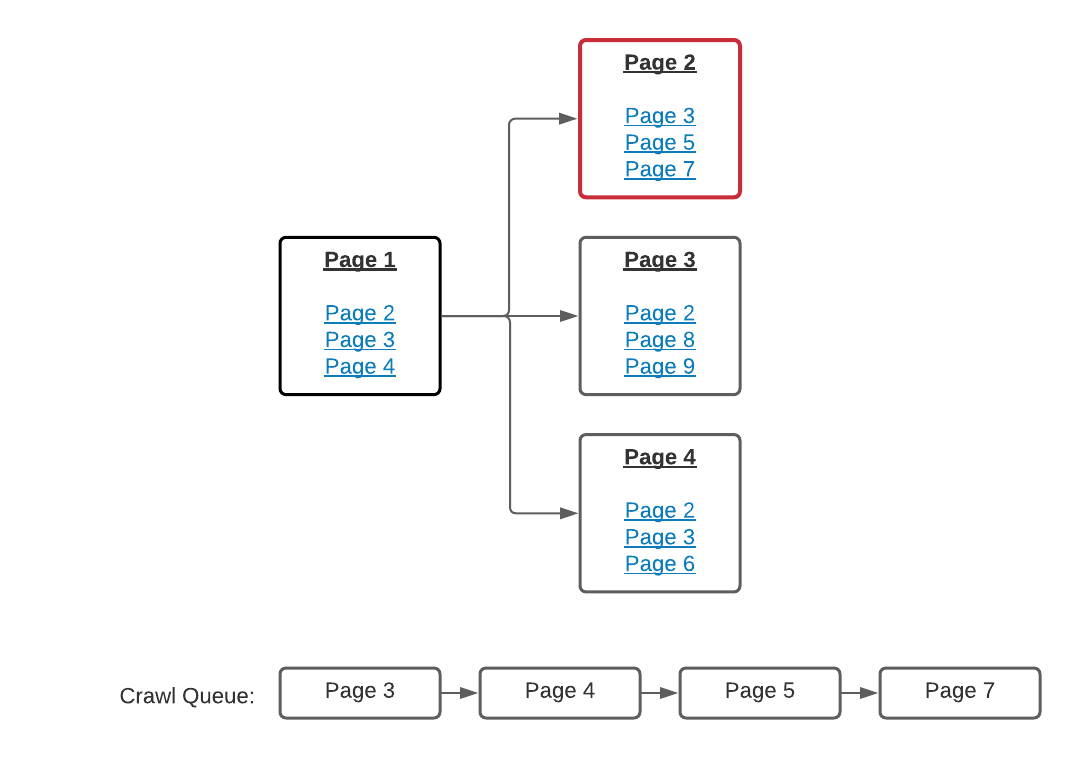 And on-and-on it goes until the full site has been downloaded. For the most basic class of crawler we want to keep a list of the pages we’ve already seen so that we don’t add them to the queue again. For special classes of crawlers (e.g. Googlebot) the crawling will be continuous, so pages can go back onto the crawl queue under certain conditions.
And on-and-on it goes until the full site has been downloaded. For the most basic class of crawler we want to keep a list of the pages we’ve already seen so that we don’t add them to the queue again. For special classes of crawlers (e.g. Googlebot) the crawling will be continuous, so pages can go back onto the crawl queue under certain conditions.
So a simple crawler is something a second year computer science student should be able to bash out in an afternoon. What makes ours so special that I’m writing a blog post about it? There are a couple of pretty impressive things about our crawler…
- Its speed and capacity to handle huge amounts of data.
- The kinds of data it can capture.
Data Volume and Speed
Crawls of large websites generate huge data volumes and take a long time.
Consider a site with 200,000 pages with each page containing an average of 100 links. That’s 20 million links. If each link’s anchor text has an average length of 40 characters we’re looking at over a gigabyte of storage. And that’s just anchor text! If we want to capture data about where a link occurs on a page, which modules it belongs to and so on and so forth the storage requirements increase extremely quickly.
And then there’s time. We all want to be instantly gratified and begin writing reports on our data straight away, but the reality is it’s just not possible when your site gets to a certain size. A 12 million page site being crawled at a rate of 10 pages per second will take almost two weeks to complete.
With both these issues in mind we defined our own data format specialised for the kind of data we were gathering during crawls. This provides both a high level of compression and high write concurrency.
Using this we’re able to achieve a crawl rate of over 200 pages per second and maintain a relatively low storage footprint. This means we can crawl a 12 million page site in under 17 hours. It’s not quite instant gratification, but it’s quicker than two weeks!
Link-Level Analysis
There’s another benefit of choosing to build a web crawler of our own: we capture data at the link level and are able to report on that and drill into it really closely.
What do I mean by “link-level data”? I mean we can collect categorical data about individual links based on the elements around them on the page. Is the link element discoverable with a particular CSS selector? Is its parent element? Does one of its ancestors contain a title tag which matches a given regular expression? This is the kind of link-level data we collect.
This means we can answer questions as granular as “how many links in module X point pages for inventory in Australia? Which pages do these links occur on?”. This provides huge power when auditing to discover link wastage.
I gave an example of this in my webinar on data-driven internal link optimisation when I explained how we could use the data we gathered to show which link modules linked between which page types:
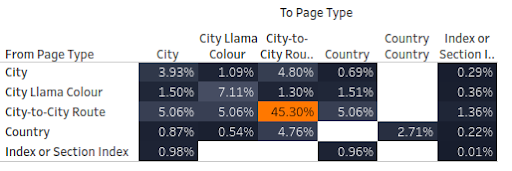 This is hugely powerful when doing internal link auditing as it allows us to isolate classes of links that may be problems on particular page types. We can even go so far as to report on how much PageRank is flowing between page types and which link modules are responsible for this. This means we can identify huge amounts of wasted links.
This is hugely powerful when doing internal link auditing as it allows us to isolate classes of links that may be problems on particular page types. We can even go so far as to report on how much PageRank is flowing between page types and which link modules are responsible for this. This means we can identify huge amounts of wasted links.
Why We Chose to Build a Web Crawler
Since we chose to build a web crawler of our own we’ve used it to crawl over 500 million URLs and analysed over 50 billion internal links. We’ve gotten better and better at structuring our result data in a way to make it quickly queryable and are continuing to work on improving our data storage.
It’s become an indispensable part of our internal link analysis tool stack, and I think with its high performance and depth of gathered data it allows us to provide unmatched data analysis.
Want to find out how our web crawler can work for you? Request a free consultation.